【Redis】有序集合的交集与并集
Redis支持多种类型的数据结构,最简单的字符串(strings),适合存储对象的哈希(hash),简单的字符串列表(list),无序集合(set),有序集合(sorted set),以及用于做基数统计的HyperLogLog,其中使用频率相对较高的便是集合。
无论是无序集合set,还是有序集合zset,集合内的元素都具有唯一性,如果插入相同的元素,都将被忽略。有时候通过业务逻辑直接存储的集合,并不能满足所有的业务需求。比如博客园可以按分类存储一个set,元素为文章id:
sadd article:type:typeid articleid
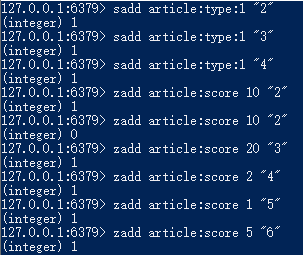
sadd article:type:1 "2"
sadd article:type:1 "3"
sadd article:type:1 "4"
按文章的点赞与踩计算出文章分数的有序集合,元素为文章id
zadd article:score score articleid
zadd article:score 10 "2"
zadd article:score 20 "3"
zadd article:score 2 "4"
zadd article:score 1 "5"
zadd article:score 5 "6"
但是如果我们需要在分类下的文章按照分数重新进行排序,怎么办?既然是集合,我们能想到操作就是,取交集,并集,差集。
1.zinterstore-交集
取这俩集合的交集,就可以完成上面的需求。
zinterstore 可以计算多个有序集合的交集(无序集合的score为0),并生成新的有序集合。
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight] [SUM|MIN|MAX]
-
numkey:操作的集合数 -
weights:是一个可选参数,乘法因子 -
aggregate:聚合,默认是求和SUM
如果destination新key存在,就被覆盖。
zinterstore article:score:1 2 article:type:1 article:score aggregate max
计算上面两个集合的交集,以取最大值的方式聚合。
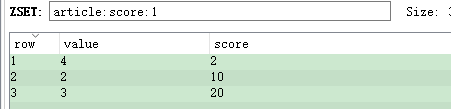
然后就可以通过zrevrange命令按分数从大到小:
zrevrange article:score:1 0 -1

2.zunionstore-并集
上面在交集中没有用到乘法因子,我们将在并集中介绍:乘法因子用于所有的元素的score值在传递给聚合函数之前都要先乘以这个因子,说白了,先weights后aggregate。我们就用官方示例说明:
redis> ZADD zset1 1 "one"
(integer) 1
redis> ZADD zset1 2 "two"
(integer) 1
redis> ZADD zset2 1 "one"
(integer) 1
redis> ZADD zset2 2 "two"
(integer) 1
redis> ZADD zset2 3 "three"
(integer) 1
redis> ZUNIONSTORE out 2 zset1 zset2 WEIGHTS 2 3
(integer) 3
redis> ZRANGE out 0 -1 WITHSCORES
1) "one"
2) "5"
3) "three"
4) "9"
5) "two"
6) "10"
redis>
按交集操作,key为out的元素只会有one two,但是如果取并集,元素就会有one two three ,默认聚合函数为SUM
所以最终元素:
one- 1x2=2
- 1x3=3
- SUM(2+3)=5
two- 2x2=4
- 2x3=6
- SUM(4+6)=10
two- 0x2=2
- 3x3=9
- SUM(0+9)=9
3.总结
无论是取交集还是并集
- 以元素为基准做并集与交集操作
score值先与weights乘法因子计算,如果有指定乘法因子的- 执行聚合函数,
aggregate(),默认SUM,还有MIN MAX
ps:集合操作是要花费时间的,实际操作时,生成的集合key应该设置过期时间,短时间查询,应该不做交集或并集操作,过期后,才重新做计算。

- 原文作者:Garfield
- 原文链接:http://www.randyfield.cn/post/2021-04-21-go-redis/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。