【Kafka】kafka使用之路(一)初识
Apache Kafka由Linkedin开发,最初是被设计用来解决Linkedin公司内部海量日志传输等问题;其由Scala编写,于2011年开源并进入Apache孵化器,2012年10月毕业,现为Apache顶级项目。
1.什么是kafka
Kafka是一个分布式数据流平台,可以运行在单台服务器上,也可以在多台服务器上部署形成集群;提供了发布和订阅功能,使用者可以发送数据到kafka中,也可以从kafka中读取数据。具有高吞吐、低延迟等特点。
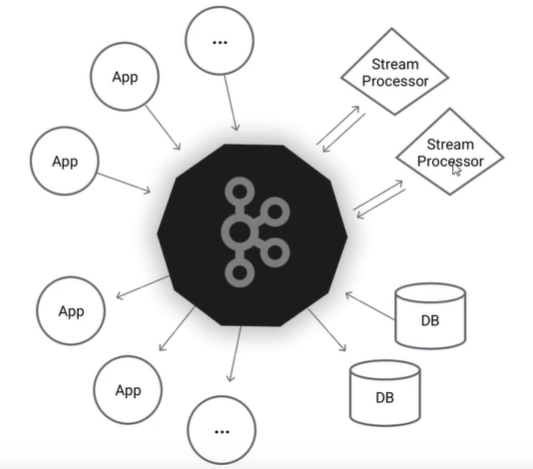
2.kafka各组件说明
2.1 架构图
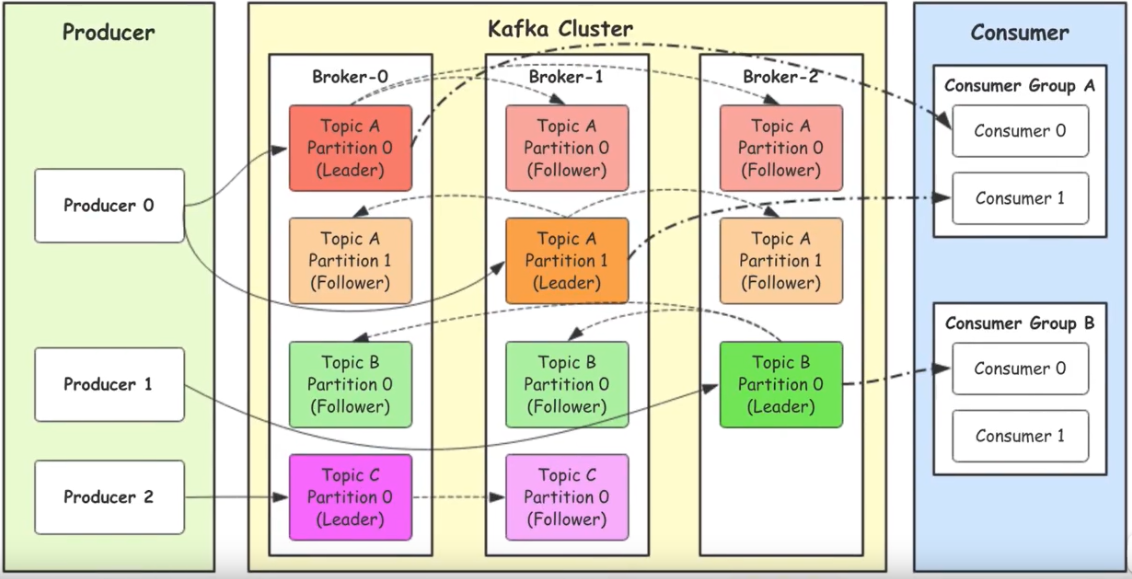
2.2 组件简介
- Producer:生产者,消息的产生者,是消息的入口
- Kafka cluster:
kafka集群,一台或多台kafka节点组成:- Broker:
Broker是指部署了Kafka实例的节点,可以一个服务器有多个kafka实例,也可以一个服务器一个kafka实例。每个kafka集群内的broker都有一个 不重复 的编号,如上图的broker-0broker-1… … - Topic: 消息的主题,可以理解为消息的不同类型,
kafka的数据就保存在topic。在每个broker上都可以创建多个topic。实际应用中通常一个业务线建一个topic. - Partition:
Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个kafka在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹。 - Replication:每一个分区都有多个副本。当主分区Leader故障的时候会选择一个Follower上位,成为Leader。
kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只能存放一个副本(包括自己)
- Broker:
- Consumer: 消费者,消息的消费方,是消息的出口。
- Consumer Group:可以将多个消费者组成一个消费者组,在
kafka的设计中,同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量。
- Consumer Group:可以将多个消费者组成一个消费者组,在
2.3 选择partition的原则
在kafka中,如果某个topic有多个分区,生产者怎么知道把数据发往哪个分区?
kafka中有几个原则:
partition在写入时候可以指定需要写入的partition,如果有指定,则写入对应的partition,- 如果没有指定
partition,但是设置了数据的key,则会根据key的值hash出一个partition, - 如果既没有指定
partition,也没有设置key,则会采用轮询的方式,即每次取一小段时间的数据写入某一个partition,下一段的时间写入下一个partition。
2.4 Topic和数据日志
topic是同一类别的消息记录record的集合。在kafka中,一个主题通常有多个订阅者。对于每个主题,kafka集群维护了一个分区数据日志文件,结构如下图:
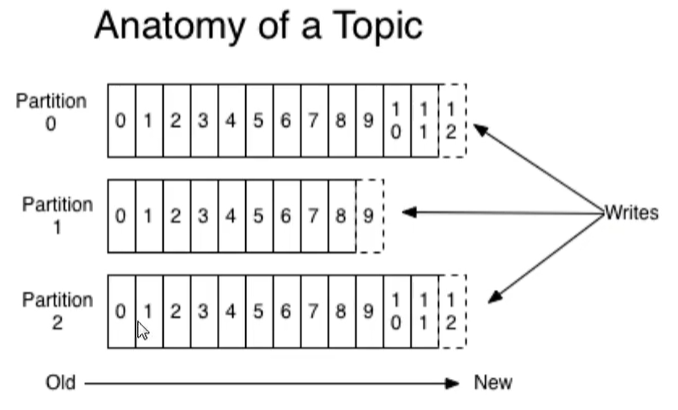
每个分区都有一个有序并且不可变的消息记录集合。当新的数据写入时,就被追加至分区的末尾。在每个分区中,每条消息都会被分配一个顺序的唯一标识,这个标识被称为偏移量offset,这个偏移量也是能够快速检索消息准备了条件。所以看上面的图,kafka只能保证在同一个分区的内部,消息是有序的,不同分区,就无法保证了
其次,kafka还可以配置一个保留期限,用来标识日志在kafka集群内保留多长时间。 kafka集群会保留在保留期限内所有被发布的消息,不管这些消息是否被消费。 例如,保留期限设置为两天,数据发布至kafka集群:
- 两天内,所有的这些数据都可以被消费
- 超过两天,这些数据将会被清空
由于kafka会将数据进行持久化存储(即写入到硬盘上),所以保留的数据大小可以设置为一个比较大的值。
2.5 partition结构
partition在服务器上的表现形式就是一个一个的文件夹,每个partition的文件夹下面会有多组segment文件,每组segment文件又包含.index文件、.log文件、.timeindex文件是哪个文件,其中.log文件就是实际存储message的地方,而.index和.timeindex文件为索引文件,用于检索消息。
2.6 消费者组
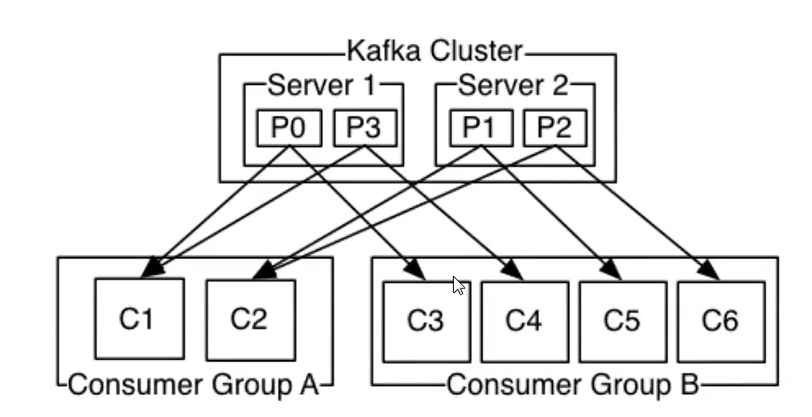
每个分区最多只能被消费者组的一个实例消费,换句话总结:一个分区只能被一个消费者组消费
3.kafka工作流
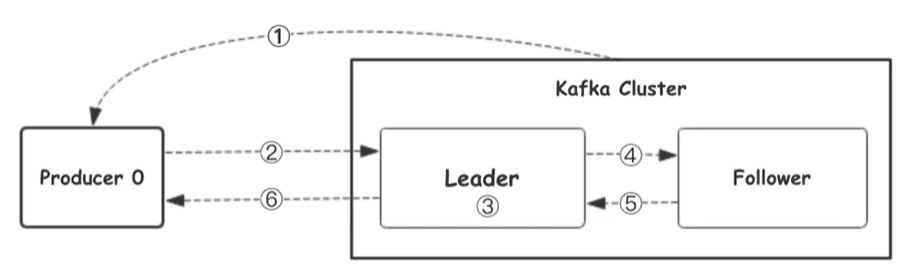
- ①生产者从
kafka集群中获取分区leader信息 - ②生产者将消息发送给
leader - ③
leader将消息写入本地磁盘 - ④ **
follower从leader拉取消息数据 ** - ⑤
follower将消息写入本地磁盘后向leader发送ACK确认 - ⑥
leader收到所有的follower的ACK之后向生产者发送ACK确认
3.1 ACK应答机制
上面提到几次ACK,生产者在向kafka写入消息的时候,可以设置参数来确认是否确认kafka接收到数据,这个参数可以设置的值为0、1、all。
- 0-代表
producer往集群发送数据而不需要等待集群返回,不确保消息发送成功。安全性最低但是效率最高。 - 1-代表
producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。 - all-代表
producer往集群发送数据需要等到所有的follower都完成从leader的同步才会发送下一条,确保leader发送成功和所有副本都完成备份。安全性最高,但是效率最低。
注意: 如果往不存在的topic写数据,kafka会自动创建topic,partition,replication,数量默认配置都为1
4.使用场景
4.1 消息队列
在系统架构设计中,经常会使用消息队列MQ。这是一种跨进程的通信机制,用于上下游的消息传递,使用MQ可以使上下游解耦,消息发送上游只需要依赖MQ,逻辑上和物理上都不需要依赖其他下游服务。常见使用如流量削峰、数据驱动的任务依赖。在MQ领域,除了Kafka还有其他很多,如RabbitMQ。
4.2 追踪网站活动
现在的大数据分析太可怕了,前一秒看过什么,浏览过什么,下一秒就开始推荐商品,推荐新闻。要推荐就需要追踪用户操作。这也是kafka最初被设计出来的目的:网站活动(PV、UV、搜索记录)的追踪。可以将不同的活动放入不同的topic,供后续的实时计算、实时监控等程序使用,也可以将数据导入到数据仓库中,进行后续的离线处理如大数据分析、报表生成等等。
4.3 Metrics指标
kafka经常被用来传输监控数据、日志数据等等。主要用来聚合分布式应用程序的数据,将数据集中后进行统一的分析和展示。
日志聚合
日志聚合通常指将不同服务器的日志收集并放入日志中心,比如文件服务器或者HDFS中的一个目录,供后续进行分析处理。比如elasticsearch,供后续检索。
物联网设备数据聚合
物联网应用平台会有很多设备,这些设备会实时或者准实时的回传数据,对回传的数据做一个收集,供后续分析处理,例如利用时序数据库对设备的回传数据进行一个存储,然后生成各种可视化图表。
5.zookeeper简介
如果没有 ZooKeeper,Kafka 将无法运行,因为kafka默认是用zookeeper做集群管理。所以有必要了解一下zookeeper。
但是有一篇文章,深度解读:Kafka 放弃 ZooKeeper,消息系统兴起二次革命,不知道什么情况,至少最新的kafka稳定版,依然需要zookeeper
zookeeper的功能大概就跟etcd差不多,在之前的博文【etcd】etcd使用与集群搭建已经有介绍了,不再赘述:
- 服务注册/服务发现
- 分布式锁
本篇就介绍到这。

- 原文作者:Garfield
- 原文链接:http://www.randyfield.cn/post/2021-05-05-kafka/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。